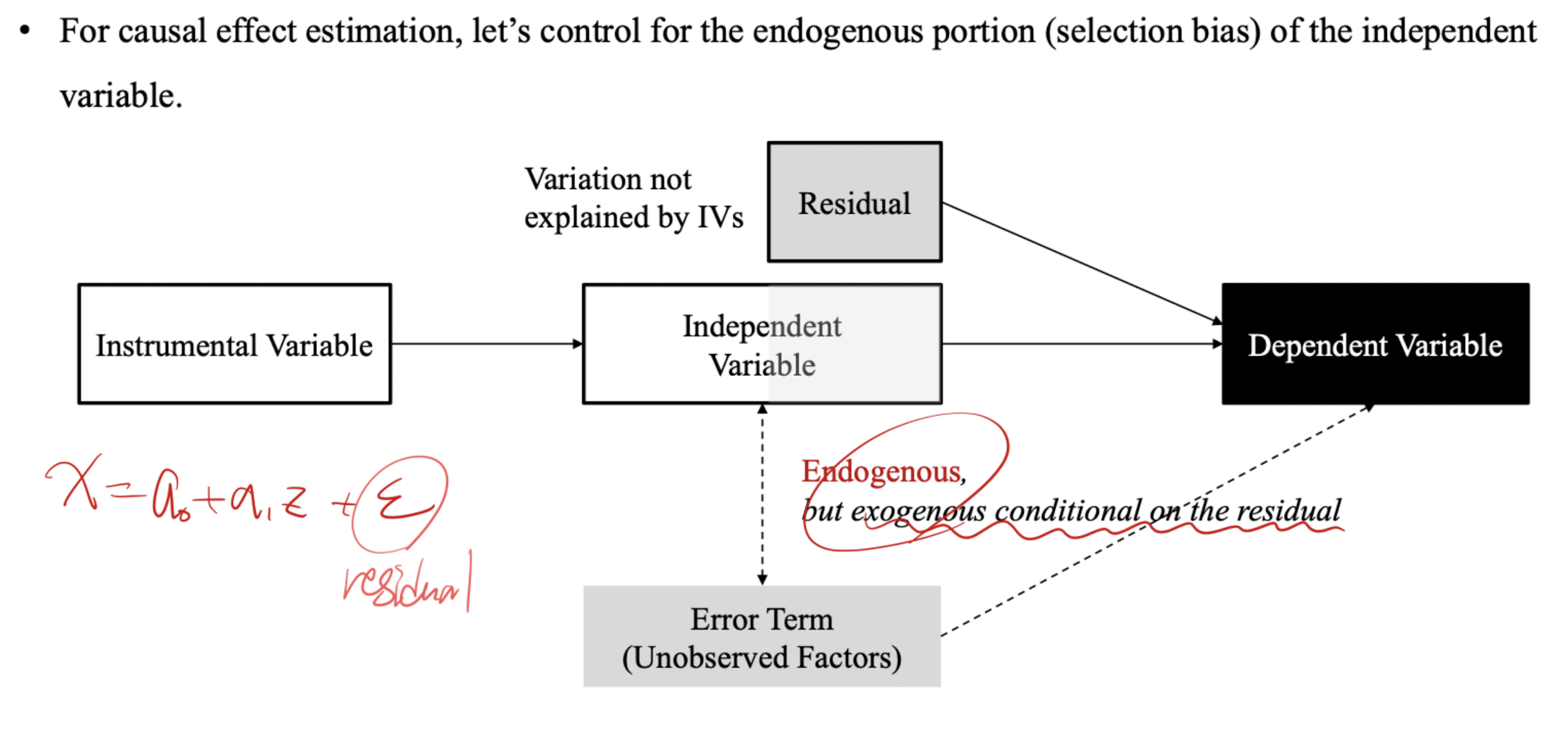
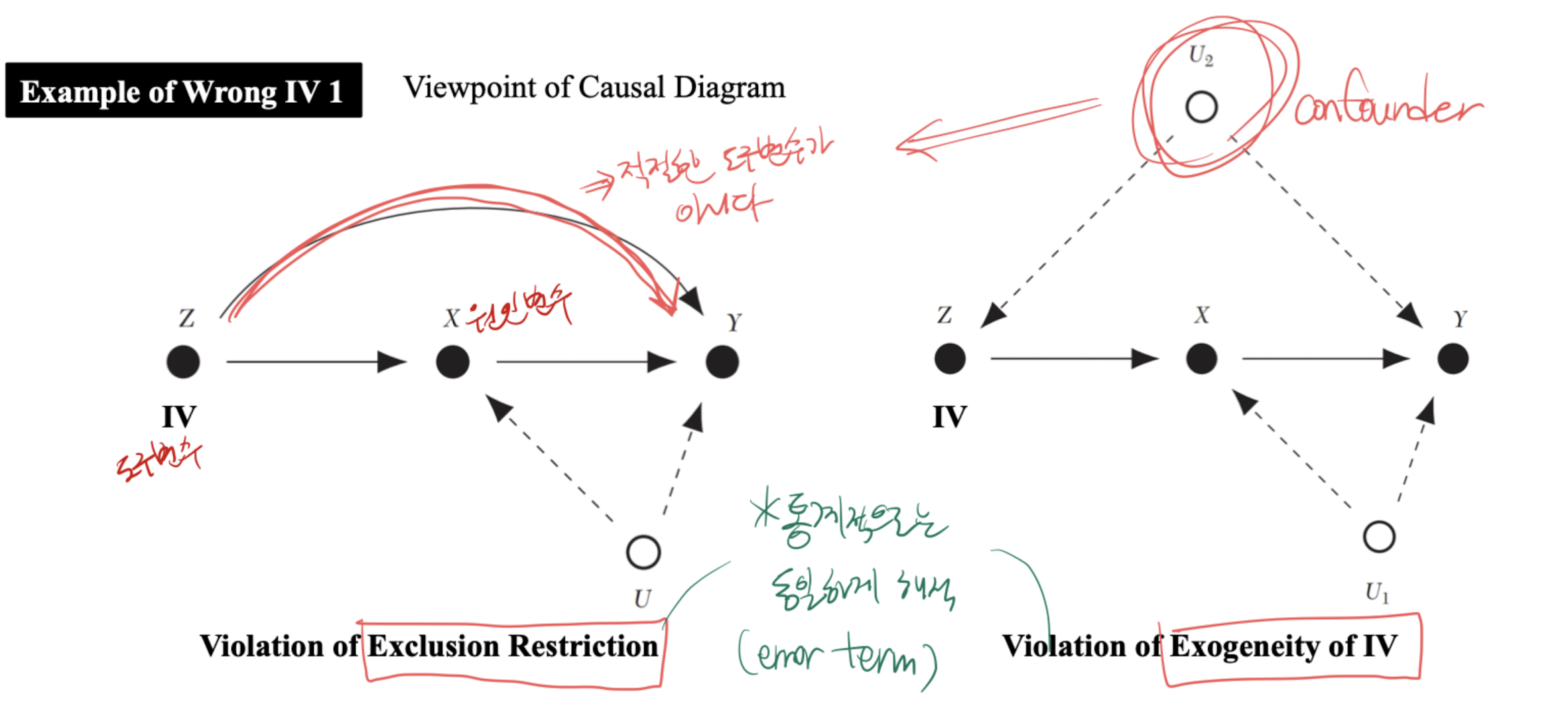
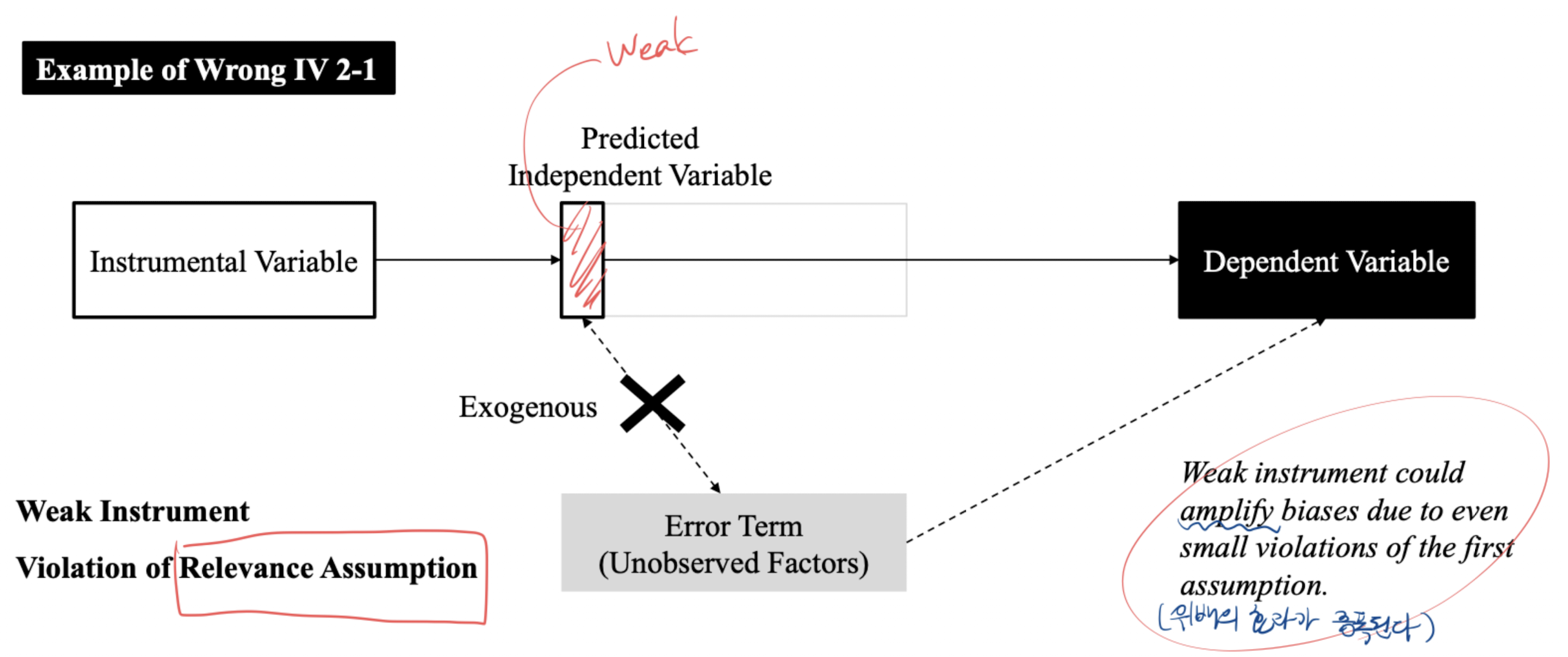
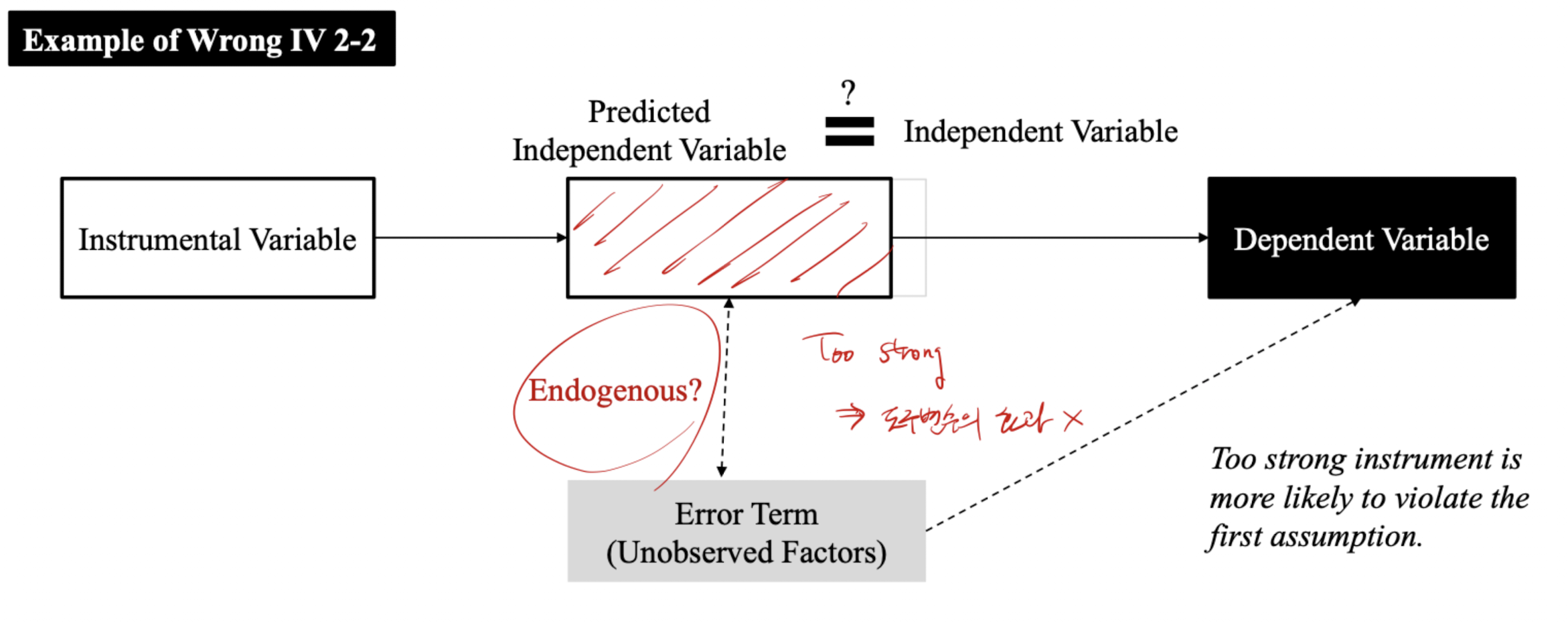
프랜시스 골턴과 골턴 보드: regression toward the mean
- 프랜시스 골턴은 유전을 통해 형질이 발산하지 않는 것(키 큰 부부의 자녀들이 더 키가 크지 않고 부부보다 오히려 작은 현상)이 유전이 갖는 물리적인 특성이라고 추측했다.
- 다시 말해, 평균으로의 회귀가 이런 유전의 특성이 가져오는 인과적인 결과로 해석했다.
- 이 해석은 (당연히) 잘못된 해석이지만, 골턴의 regression을 해석하기 위한 접근은 최초로 상관관계(correlation)라는 개념을 탄생시켰다.
Galton and the Abandoned Quest
작가의 주장
- 골턴과 피어슨의 주도로 진행된 통계학의 발전은, 통계학계를 model-blind data-reduction 단체로 만들어버렸다.
- correlation의 발견과 고도화에만 집중한 나머지, causality의 발전은 경시되고 낙후될 수 밖에 없었다.
Pearson: The Wrath of The Zealot
- 피어슨은 상관관계가 전부고, 통계학과 과학이 추구해야할 것은 상관관계를 검증하는 것뿐이라고 강조했다.
- 피어슨은 인과관계란 두 모집단(변수)을 부적절하게 조합했을 때 발생하는 잘못된 해석이라고 주장했다.
- 피어슨과 그 제자들이 당대 통계학의 주류였고 그들은 인과관계에 매우 적대적이었기 때문에, 오랜 세월동안 라이트가 반론을 제기하기 전까지 인과관계에 대한 연구는 매우 미미했다.
Sewall Wright, Guinea Pigs, and Path Diagrams
- 라이트는, path diagram을 활용해 기니피그의 털 색깔이 어떻게 유전되는지를 연구했고, 인과 모델과 통계학을 조합한 최초의 연구사례를 남겼다.
- 하지만, 당대 주류인 통계학계로부터 무수히 많은 공격을 받았다.
- 당시 공격하는 사람들의 논리
- 인과 모델을 그래프로 표현하는 것은 불가능하다.
- 인과 모델이 맞는지를 검증할 수 없기 때문에, 이를 현실에 적용하는 것은 신뢰할 수 없다.
- 라이트의 주장:인과 모델(가설) 없이는 인과 관계 해석(발견)은 불가능하다.
- 처음 도안한 인과 모델(가설)이 잘못되었음이 데이터로 검증되면, 다른 인과 모델(새로운 가설)로 검증하면 된다.
- 라이트의 연구 방법론은 상관관계에서 인과관계를 뽑아내는 게 아니라, 가설과 상관관계를 조합하여, 어떤 인과 현상을 설명하는 것
E PUR SI MUOVE (And Yet It Moves)
출산시 기니피그 무게에 대한 예시
- 자궁에서 67일 보낸 태아가, 66일 보낸 태아보다 5.66g 더 무겁다.
- 결론: 하루에 5.66g씩 자라는가?
- No!
- 이전의 무게와 자궁의 크기 등이 주는 요인들이 있다.
- 이를 인과 그래프로 표현하고 계산하면 하루에 몇 g씩 자라는지 규명 가능하다. (연립 방정식 문제로 치환된다.)
라이트는 통계학이 단순히 방법론의 집합이라는 피셔의 주장을 극혐했다.
- 방법론뿐만 아니라 데이터가 어떻게 생성되는지(인과 모델)에 대한 이해를 통합해야 한다고 주장했다.
주류 통계학은 모델을 가정하지 않고 데이터를 통해서도 (잘 가공만 하면) 과학적 인사이트를 도출할 수 있다고 주장했지만, 필자는 이런 식의 "모델 없는" 데이터 해석은 1단계 수준의 인과 추론만 가능할 뿐, 더 높은 단계로는 갈 수 없다고 주장한다.
From Objectivity to Subjectivity - The Bayesian Connection
- 상관관계 해석을 포함한 다른 주류 통계학과 달리, 인과 추론은 분석가에게 주관적 해석을 요구한다.
- 베이지안 분석론: Prior Belief + New Evidence -> Revised Belief
- 베이지안 분석론의 장점은, 데이터 양이 많아지면 결국 하나의 객관적인 진실로 우리의 믿음을 수렴시킬 수 있다는 것이다.
- 그동안 인과추론 연구가 배척받아 왔기 때문에, 다른 분야 대비 방법론을 적용하고 설명하는 데에 필요한 언어가 부족하다.
- 이런 언어들이 향후 챕터에서 더 소개될 예정
'Statistics > Causal Inference' 카테고리의 다른 글
| [The Book of Why] 4. Confounding and Deconfounding: Or, Slaying the Lurking Variable (0) | 2023.06.19 |
|---|---|
| [The Book of Why] 3. From Evidence to Causes: Reverend Bayes Meets Mr. Homles (0) | 2023.06.18 |
| [The Book of Why] 1. The Ladder of Causation (0) | 2023.05.07 |
| [The Book of Why] 0. Mind Over Data (0) | 2023.05.05 |
| Session 9. Instrumental Variables [9-1] 도구 변수 (Instrumental Variables) (0) | 2022.04.17 |