3-1. 대규모 분산 처리의 프레임워크
구조화 데이터와 비구조화 데이터
- 스키마: 칼럼명, 데이터형, 테이블 간의 관계 등이 정의된 정보
- 구조화된 데이터 (Structured Data): 스키마가 명확하게 정의된 데이터 (SQL로 집계)
- 비구조화 데이터 (Unstructured Data): 텍스트, 이미지, 동영상 등의 미디어 데이터로 스키마가 없는 데이터 (SQL로 집계 불가)
- 데이터 레이크: 비구조화 데이터를 분산 스토리지 등에 저장하고, 분산 시스템에서 처리하는 것
- 데이터 가공 과정에서 스키마 정의 => 구조화된 데이터로 변환 => 분석에 사용
스키마리스 데이터
- 스키마리스 데이터(shemaless data): CSV, JSON, XML 등 데이터 서식은 정해져 있지만, 칼럼 수나 데이터형은 명확하지 않은 데이터
- 스키마를 정하는 것은 시간과 비용이 소요되기 때문에 JSON은 그대로 저장하고 데이터 분석에 필요한 필드만 추출하는 편이 가장 간단
데이터 구조화의 파이프라인
- 먼저 필요한 것은 스키마를 명확하게 한 테이블 형식의 '구조화 데이터'로 변환하는 것
- 구조화 데이터는 일반적으로 데이터 압축률을 높이기 위해 열 지향 스토리지로 저장
- 데이터 마트는 고려하지 않고, 데이터를 구조화하여 SQL로 집계 가능하게 만드는 것만 생각
열 지향 스토리지의 작성
- 분산 스토리지 상에 작성해 효율적으로 데이터 집계
- MPP 데이터베이스: 제품에 따라 스토리지 형식이 고정되어 있어 사용자가 그 상세를 몰라도 됨
- Hadoop: 사용자가 직접 열 지향 스토리지 형식을 선택, 쿼리 엔진도 선택
- Hadoop에서 선택할 수 있는 열 지향 스토리지 종류:
- Apache ORC: 구조화 데이터를 위한 열 지향 스토리지
- Apache Parquet: 스키마리스에 가까운 구조로 되어있어 JSON 같은 데이터도 그대로 저장 가능
- 비구조화 데이터를 열 지향 스토리지로 변환하는 과정에는 데이터 가공 및 압축을 위해 많은 컴퓨터 리소스가 소비됨
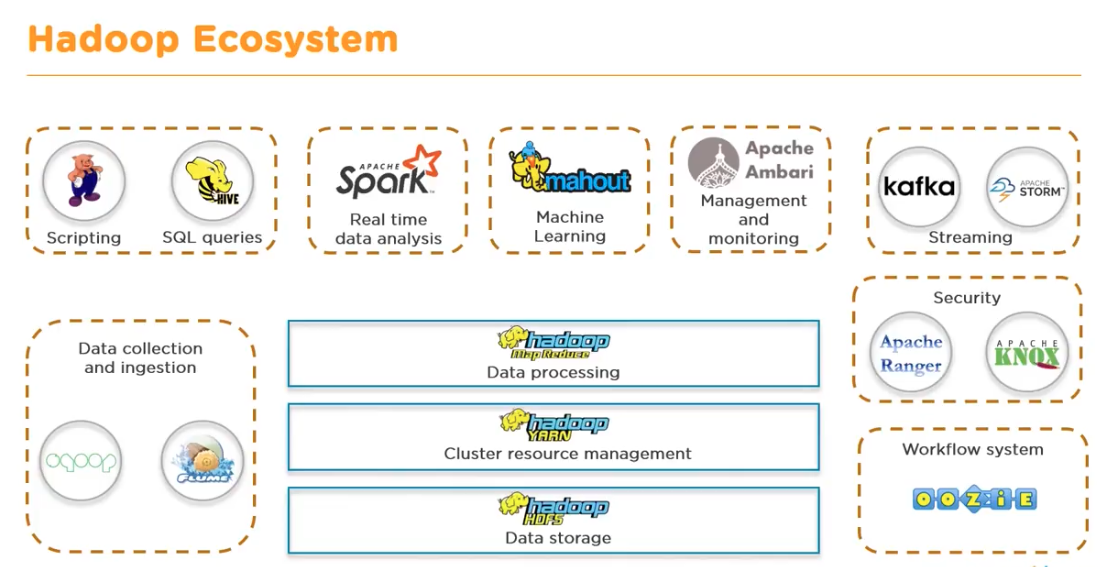
Hadoop - 분산 데이터 처리의 공통 플랫폼
- Hadoop: 분산 시스템을 구성하는 다수의 소프트웨어로 이루어진 집합체 (대규모 분산시스템을 구축하기 위한 공통 플랫폼 역할 담당)
분산 시스템의 구성 요소
Hadoop의 기본 구성 요소
1. HDFS (Hadoop Distributed File System): 분산 파일 시스템
2 YARN (Yet Another Resource Negotiator): 리소스 관리자
3. MapReduce: 분산 데이터 처리
- 그 외의 프로젝트는 Hadoop 본체와 독립적으로 개발되어 Hadoop을 이용한 분산 애플리케이션으로 동작
- Hadoop을 일부만 사용하거나 전혀 사용하지 않게 분산 시스템을 구성할 수도 있다
분산 파일 시스템과 리소스 관리자: HDFS, YARN
- HDFS: Hadoop에서 처리되는 데이터 대부분이 저장됨
- 다수의 컴퓨터에 파일을 복사하여 중복성을 높임
- YARN: CPU나 메모리 등 계산 리소스 관리
- 컨테이너 (container): 애플리케이션이 사용하는 CPU 코어와 메모리를 관리하는 단위
- Hadoop이 분산 애플리케이션을 실행하면 YARN이 클러스터 전체의 부하를 보고 비어있는 호스트부터 컨테이너를 할당
- (Docker 컨테이너와 무관)
- 한정된 리소스를 여러 애플리케이션에 어떻게 할당할 지 관리하므로써 모든 애플리케이션이 차질없이 실행되도록 제어
분산 데이터 처리 및 쿼리 엔진: MapReduce, Hive
- MapReduce: YARN 상에서 동작하는 분산 애플리케이션 중 하나
- Java 프로그램을 실행할 수 있음 - 비구조화 데이터를 가공하는 데 적합
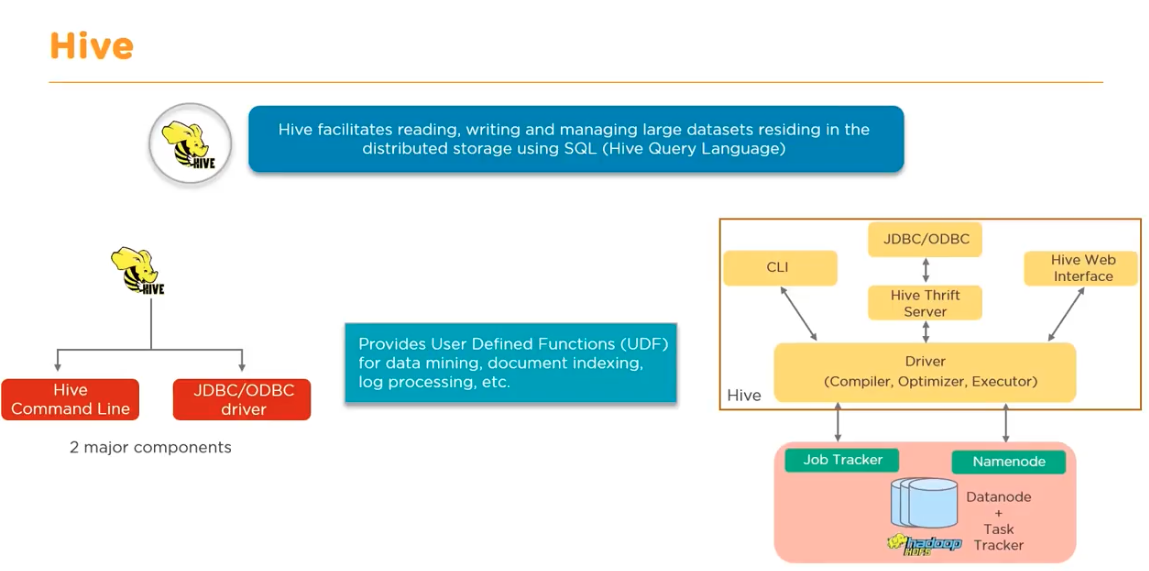
- Apache Hive: SQL 등 쿼리 언어에 의한 데이터 집계시 사용하는 쿼리 엔진
- 초기 Hive: SQL 쿼리를 자동으로 MapReduce 프로그램으로 변환하는 소프트웨어로 개발
Hive on Tez
- Hive를 가속화하기 위해 개발
- 기존 MapReduce는 오버헤드가 매우 컸음 => 애드 혹 쿼리 실행에 부적합
- Tez에서는 스테이지 종료를 기다리지 않고 처리가 끝난 데이터를 차례대로 후속 처리에 전달하므로써 쿼리 전체 실행 시간 단축
대화형 쿼리 엔진
- (Hive 고속화 말고) 처음부터 대화형 쿼리 실행만 전문으로 하는 쿼리 엔진 개발
- Presto, Apache Impala
- 대화형 쿼리 엔진: 순간 최대 속도를 높이기 위해 모든 오버헤드 제거
- 사용할 수 있는 리소스를 최대한 활용하여 쿼리 실행
- MPP 데이터베이스와 비교해도 손색없는 응답 시간 실현
목적에 따른 쿼리 엔진 구분
- Hive: 대량의 비구조화 데이터를 가공하는 무거운 배치 처리에 활용 (높은 처리량 (Throughput)이 특징)
- Presto, Impala: 구조화 데이터를 대화식으로 집계 (적은 지연이 특징)
SQL-on-Haddop: Hadoop 에서 개발된 쿼리 엔진들
- 아직 MPP 데이터베이스 만큼 기능적으로 따라잡지 못한 부분들이 있지만, 분산 스토리지에 저장된 데이터를 신속하게 집계할 수 있는 점에서 우수
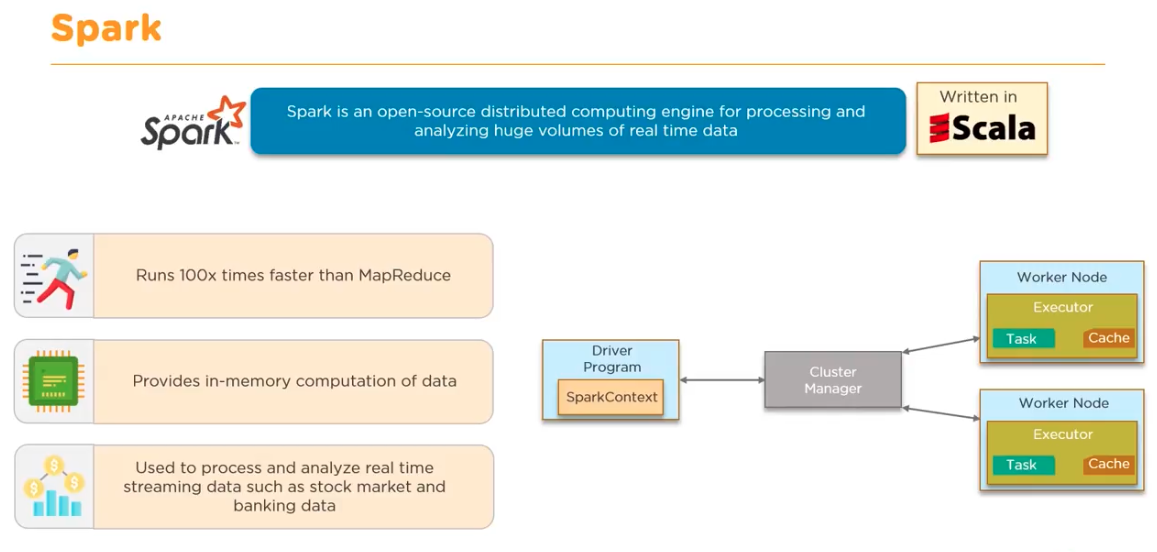
Spark - 인 메모리 형의 고속 데이터 처리
Hadoop과는 다른 독립된 프로젝트
- Spark의 대표적 특징: 대량의 메모리를 활용하여 고속화
- MapReduce는 처리 대부분을 디스크 읽고 쓰기에 사용
- 컴퓨터 메모리 성능이 높아짐에 따라, 가능한 한 많은 데이터를 메모리 상에 올려놓고 디스크에는 아무것도 기록하지 않는 것이 현실화됨
MapReduce 대체하기
Spark은 Hadoop을 대체하는 것이 아니라 MapReduce를 대체
- HDFS, YARN 등은 Spark에서도 그대로 사용
- 분산 스토리지로 Amazon S3를 이용하거나 Cassandra 등의 분산 데이터베이스를 사용하는 것도 가능
- Spark 상에서 실행되는 데이터 처리는 스크립트 언어를 사용할 수 있음: Java, Scala, Python, R
- Spark SQL: Spark 상에서 SQL 쿼리 실행
- Spark Streaming: 스트림 처리
3-2. 쿼리 엔진
SQL-on-Hadoop에 의한 데이터 처리의 구체적인 예:
- Hive에 의한 구조화 데이터 생성
- Presto에 의한 대화식 쿼리
데이터 마트 구축의 파이프라인
1. 분산 스토리지에 저장된 데이터를 구조화하고 열 지향 스토리지 형식으로 저장
- 다수의 텍스트 파일을 읽어들여 가공하는 부하가 큰 처리: Hive 사용
2. 완성한 구조화 데이터를 결합, 집계하고 비정규화 테이블로 데이터 마트에 작성
- 열 지향 스토리지를 이용한 쿼리 실행: Presto 사용
- Hive Metastore: Hive에서 만든 각 테이블의 정보
- Hive 뿐만 아니라 다른 SQL-on-Hadoop의 쿼리 엔진에서도 공통의 테이블 정보로 참고됨
Hive에 의한 구조화 데이터 작성
Hive 시작 후 CREATE EXTERNAL TABLE로 외부 테이블 정의
- 외부 테이블 (external table): Hive의 외부에 있는 특정 파일을 참고해 마치 거기에 있는 테이블이 존재하는 것처럼 읽어들일 수 있음
- 텍스트 파일 로드되고 구조화 데이터로 변환됨
- SQL-on-Hadoop의 쿼리 엔진들은 MPP 데이터베이스와 달리, 데이터를 내부로 가져오지 않아도 텍스트 파일을 그대로 집계할 수 있음
- CSV 파일 등을 그대로 집계하는 것은 비효율 (매번 텍스트를 읽어야 하기 때문에 느림)
=> 열 지향 스토리지로 변환
열 지향 스토리지로의 변환: 데이터 집계의 고속화(배치형 쿼리 엔진용)
- 테이블을 열지향 스토리지 형식 (ex. ORC 형식)으로 변환
- 변환에는 다소 시간이 걸리지만, 변환 후 집계 시간 크게 단축
Hive로 비정규화 테이블을 작성하기
- 데이터 구조화가 완료되면 데이터 마트 구축
- Presto 같은 대화형 쿼리 엔진을 사용할 것인지, Hive 같은 배치형 쿼리 엔진을 사용할 것인지 결정
- 시간이 걸리는 배치 처리는 원칙적으로 Hive 사용
- 수억 레코드는 데이터 마트로 내보내는 것만으로도 상당한 시간 소요
- 쿼리 엔진 자체의 성능으 최종적인 실행 시간에 영향 거의 없음
- 리소스 효율 측면에서, 배치형 시스템 사용하는게 더 좋음
- 비정규화 테이블 생성시 효율적일 쿼리를 작성하는 것이 중요
서브 쿼리 안에서 레코드 수 줄이기
- 초기 단계에서 팩트 테이블 작게 하기
데이터 편향 피하기
- 중복 없는 값 세기 (count distinct ...)는 데이터를 한 곳에 모아야 해서 분산 처리하기 어려움
대화형 쿼리 엔진 Presto의 구조
작은 쿼리를 여러 번 실행하는 대화형 데이터 처리에는, 실행의 지연을 감소시키는 것이 필요
- 참고 기술: Dremel
플러그인 가능한 스토리지
Presto의 주요 특징: 하나의 쿼리 안에서 여러 데이터 소스에 연결 가능
- Presto는 전용 스토리지를 갖고 있지 않아, Hive와 마찬가지로 다양한 데이터 소스에서 직접 데이터를 읽어 드림
- MPP 데이터베이스에서는 소티리지와 컴퓨팅 노드가 밀접하게 결합되어 있어 처음에 데이터를 로드하지 않으면 집계를 시작할 수 없음
- Presto가 성능을 최대한 발휘하려면 원래 스토리지가 열 지향 데이터 구조로 되어 있어야 함
- ORC 형식의 로드에 최적화됨
CPU 처리의 최적화
Presto의 SQL 실행
1. 쿼리를 분석하여 최적의 실행 계획 생성
2. Java의 바이트 코드로 변환
3. 바이트 코드는 Presto의 worker 노드로 배포 -> 런타임 시스템에 의해 기계 코드로 컴파일
4. 멀티 스레드화되어 단일 머신에서 수백 태스크로 병렬 실행
- CPU 이용률이 높을 수밖에 없음
- (메모리와 CPU 리소스만 충분하다면) 데이터의 읽기 속도가 쿼리의 실행 시간을 결정
- Presto 쿼리는 일단 실행 시작되면 중간에 끼어들 수 없음
=> 너무 큰 쿼리 실행시, 그 쿼리에 대부분의 리소스가 사용되어 다른 쿼리를 실행할 수 없음
인 메모리 처리에 의한 고속화
- (Hive와 달리) Presto는 디스크에 쓰기를 하지 않음
- 모든 데이터 처리를 메모리상에서 실시하고 메모리가 부족하면 여유가 생길 때까지 기다리거나 오류로 실패
- 효과적인 데이터 처리 방식: 메모리상에서 할 수 있는 것은 메모리상에서 실행하고, 디스크가 있어야 하는 일부 데이터 처리는 Hive 등에 맡기기
- GROUP BY는 단순 반복 처리기 때문에 메모리 소비량이 거의 고정
- 대규모 배치 처리, 거대한 테이블끼리 결합 등에는 디스크 활용 필요
분산 결합과 브로드캐스트 결합
- 테이블의 결합은 종종 대량의 메모리 소비
- 분산 결합 (Distribute Join): 같은 키를 갖는 데이터는 동일한 노드에 모임
- Presto 의 기본 JOIN 방식
- 노드 간 데이터 전송을 위한 네트워크 통신 발생 => 쿼리 지연 초래
- 브로드캐스트 결합 (Broadcast Join): 결합하는 테이블의 모든 데이터가 각 노드에 복사
- 디멘전 테이블은 메모리에 충분히 들어갈 정도로 작은 것이 대부분이므로, 테이블 결합이 훨씬 빨라짐
열 지향 스토리지 집계
- Presto에서는 열 지향 스토리 집계가 매우 빠름
데이터 분석의 프레임워크 선택
MPP 데이터베이스, Hive, Presto, Spark의 장단점 비교
MPP 데이터 베이스
장점
- 완성한 비정규화 테이블의 고속 집계에 적합
- 구조화 데이터를 SQL로 집계하는 것뿐이라면 기존의 데이터 웨어하우스 제품과 클라우드 서비스 이용하는 것이 가장 좋음
- Hadoop이 데이터 웨어하우스를 능가할 수 없다
- 이 장에서 다룬 복잡한 기술 전혀 필요하지 않음
- MPP 데이터베이스는 스토리지 및 계산 노드가 일체화되어 있기 때문에, ETL 프로세스 등으로 데이터 가져오는 절차는 필요
- BI 도구와의 조합도 용이
단점
- 확장성 및 유연성 떨어짐 (아래 경우들 대응 못함)
- 대량의 텍스트 처리가 필요한 경우
- 데이터 처리를 프로그래밍하고 싶은 경우
- NoSQL 데이터베이스에 저장된 데이터를 집계하고 싶은 경우
Hive
장점
- 데이터양에 좌우되지 않음 (높은 안정성)
- Hadoop 상의 분산 애플리케이션이 원래부터 높은 확장성과 내결함성을 목표로 설계됨
- 열 지향 스토리지를 만드는 등의 무거운 처리에 적합
- Tez의 등장으로 대화형 쿼리에도 사용됨
Presto
장점
- 속도 중시 & 대화식으로 특화된 쿼리 엔진 (Hive와 정반대)
- 쿼리가 실패해도 빠르게 재실행 가능
- 많은 데이터 스토어와 조합 가능 - 모든 데이터를 SQL로 집계하게 해줌
단점
- 메모리가 부족하면 쿼리 실행할 수 없음
- 텍스트 처리가 중심이 되는 ETL 프로세스 및 데이터 구조화에는 적합하지 않음
- 열 지향 스토리지를 만드는 데 사용할 수는 있지만 적합하지는 않음
- 단시간에 대량의 리소스 소비
- 너무 무리하게 사용하면 다른 쿼리 실행 불가
Spark
장점
- 분산 시스템을 사용한 프로그래밍 환경 제공
- SQL 뿐만 아니라 스크립트 실행
- 일련의 데이터 파이프라인을 하나의 프레임워크로 작성 가능
- ETL부터 데이터 분석, 머신 러닝 등 모든 데이터 처리 가능
- 인 메모리 데이터 처리로 대화형 쿼리도 가능
단점
- 메모리 관리 등의 러닝 커브 소요
3-3. 데이터 마트의 구축
각종 테이블의 경할과 비정규화 테이블을 만들기까지의 흐름 설명
팩트 테이블 - 시계열 데이터 축적하기
팩트 테이블 작성의 두 가지 방법
1. 추가 (append): 새로 도착한 데이터만 증분으로 추가
2. 치환 (replace): 과거 데이터를 포함하여 테이블 전체 치환
테이블 파티셔닝
추가 (append)의 잠재적 문제
- 결손: 추가 실패를 알아채지 못한 경우
- 중복: 오류로 인해 추가가 여러 번 실행된 경우
- 관리의 복잡성: 팩트 테이블을 다시 만들어야 하는 경우
테이블 파티셔닝: 테이블을 물리적인 여러 파티션으로 나눔으로써 파티션 단위로 정리하여 데이터를 쓰거나 삭제할 수 있도록 함
- 각 파티션은 매번 교체 (이미 존재한다면 덮어쓰도록)하도록 설계
- 중복 해결
데이터 마트의 치환
- 데이터 마트의 양은 한정되어 있기 대문에, 상당히 거대한 테이블을 만들지 않는 한 매번 치환하는 것이 좋음
- 팩트 테이블 전체 치환하는 것의 장점
1. 중복과 결손 해결
2. 스키마 변경 등도 쉬움
- 단점: 처리 시간
- 데이터 양이 너무 많다면 오래 걸림
- 데이터 양이 너무 많다면 마찬가지로 테이블 파티셔닝을 실시하거나 모니터링을 세팅할 필요 있음
- (Small Start) 1시간 이내에 팩트 테이블을 만들 수 있다면, 매번 치환하는 것으로 충분
- 그것이 어려운 경우에만 추가를 이용한 워크플로 고려
집계 테이블 - 레코드 수 줄이기
집계 테이블 (Summary Table): 팩트 테이블을 어느 정도 모아서 집계하여 데이터 양을 줄임
- 일일 보고서를 만드는 데에 daily summary 테이블 자주 사용
- 카디널리티 (Cardinality): 각 칼럼이 취하는 값의 범위
- ex. '성별'의 카디널리티 = 2 (Male, Female), 'IP 주소'의 카디널리티 = 무한(매우 높음)
- 집계 테이블을 작게 하려면 모든 칼럼의 카디널리티를 줄여야 함
- 카디널리티를 무리하게 낮추면 원래 있던 정보가 손실 됨
- 레코드 수가 수억 건 정도면 집계 테이블을 만들지 않고 MPP 데이터베이스로 바로 써내는 것도 좋음
- 숫자 계산에 주의해야 함
- 평균값은 집계 테이블을 사용하면 제대로 계산할 수 없음 (평균의 평균 vs 전체 평균)
- count(distinct ...)도 집계 테이블로 취급하기 어려움 (daily summary table에서 MAU 계산은 불가능)
스냅샷 테이블 - 마스터 상태 기록하기
마스터 데이터처럼 업데이트될 가능성이 있는 테이블을 처리하는 두 가지 방법
1. 스냅샷 테이블 (Snapshot Table): 정기적으로 마스터 데이터를 통째로 저장
2. 이력 테이블 (History Table): 변경 내용만 저장
데이터 분석 입장에서는 스냅샷 테이블이 취급하기 쉬움
- 마스터 테이블의 레코드 수가 많다면 스냅샷 테이블은 거대해지지만 빅데이터 기술은 이걸 별로 개의치 않아도 됨
- 일종의 팩트 테이블로 간주
- 디멘전 테이블로 도 사용
- 이 때 스냅샷 날짜에 주의
- 스냅샷은 하루의 끝에 취득하는 것이 좋음
- ex. 1월 1일 스냅샷을 1월 1일 00:00:00로 하냐 vs 1월 1일 23:59:59로 하냐에 따라 트랜잭션 데이터와 결합 방식이 달라짐
- 후자 방식이 훨씬 좋다: 1월 1일 15:00:00 에 발생한 이벤트를 전자랑 JOIN하려면 데이터가 없음
- 스냅샷 테이블은 나중에 다시 만들 수 없으므로, 영구적인 저장소에 보관하여 삭제되지 않도록 주의
- 스냅샷시 처음부터 비정규화된 것이 편함
이력 테이블 - 마스터 변화 기록하기
- 변경이 있을 대마다 그 내용 기록
- 데이터 양을 줄이는 데 도움이 되지만, 어느 순간의 완전한 마스터 테이블을 나중에 복원하는 것이 어려움
- 디멘전 테이블로 사용하기 위해 별도의 처리를 통해 마스터 테이블로 복원해야 함
[마지막 단계] 디멘전을 추가하여 비정규화 테이블 완성시키기
- 팩트 테이블과 디멘전 테이블을 결합하여 비정규화 테이블 생성
'Data Engineering' 카테고리의 다른 글
| [빅데이터를 지탱하는 기술] Ch2. 빅데이터의 탐색 (0) | 2025.03.12 |
|---|---|
| [빅데이터를 지탱하는 기술] Ch1. 빅데이터의 기초 지식 (2) | 2025.02.25 |
| Hadoop Ecosystem Explained (0) | 2024.08.04 |
| [12주차] Airflow, EMR 스터디 (0) | 2022.05.08 |
| [AWS] Ubuntu EC2에서 python3 version 변경하기 (0) | 2022.04.30 |